Preface
This blog records the evolution process and lacks reference value. It is recommended to directly check the following projects and use docker for quick deployment.
Screenshots:
| Light | Dark |
|---|---|
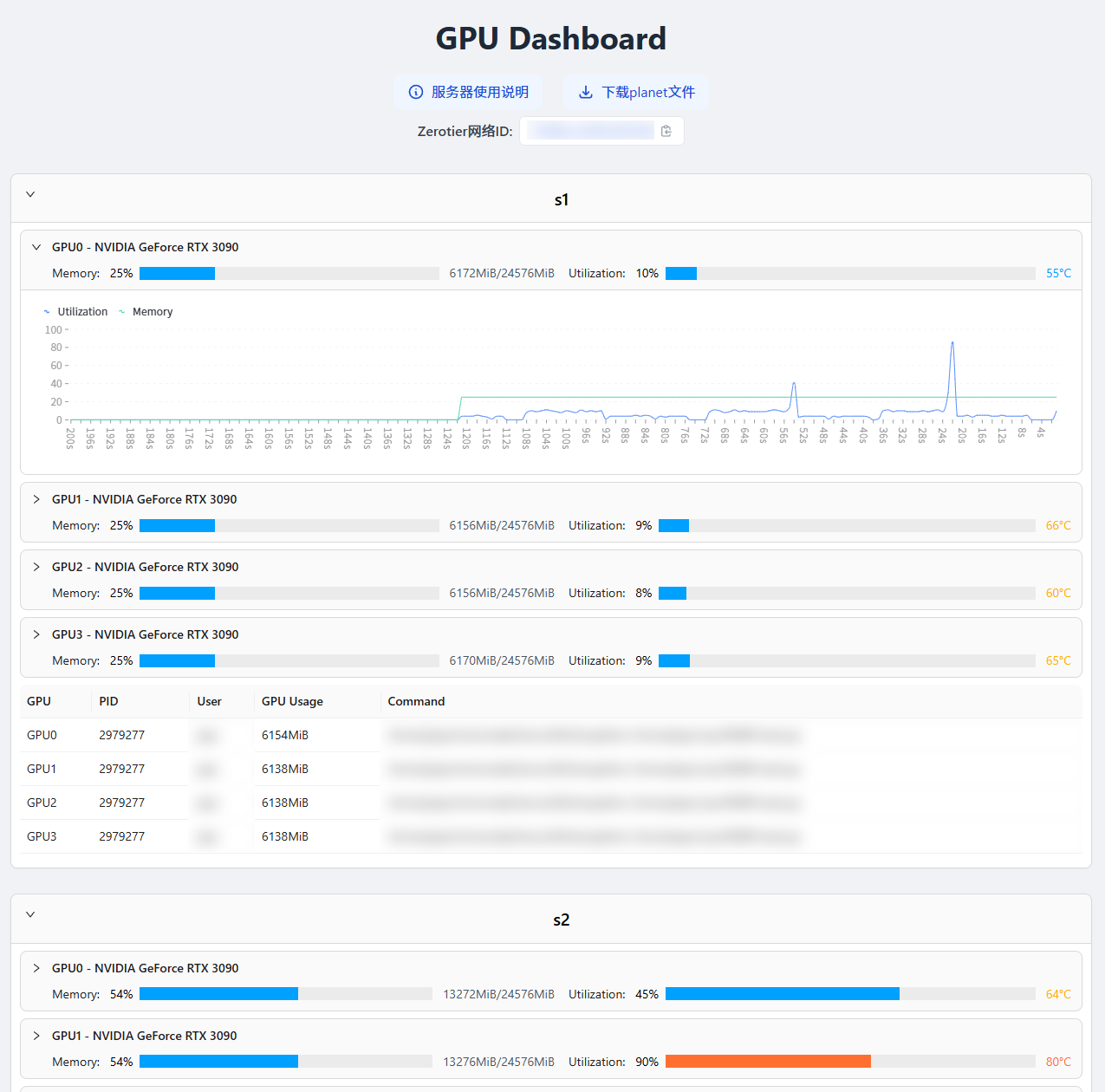 | 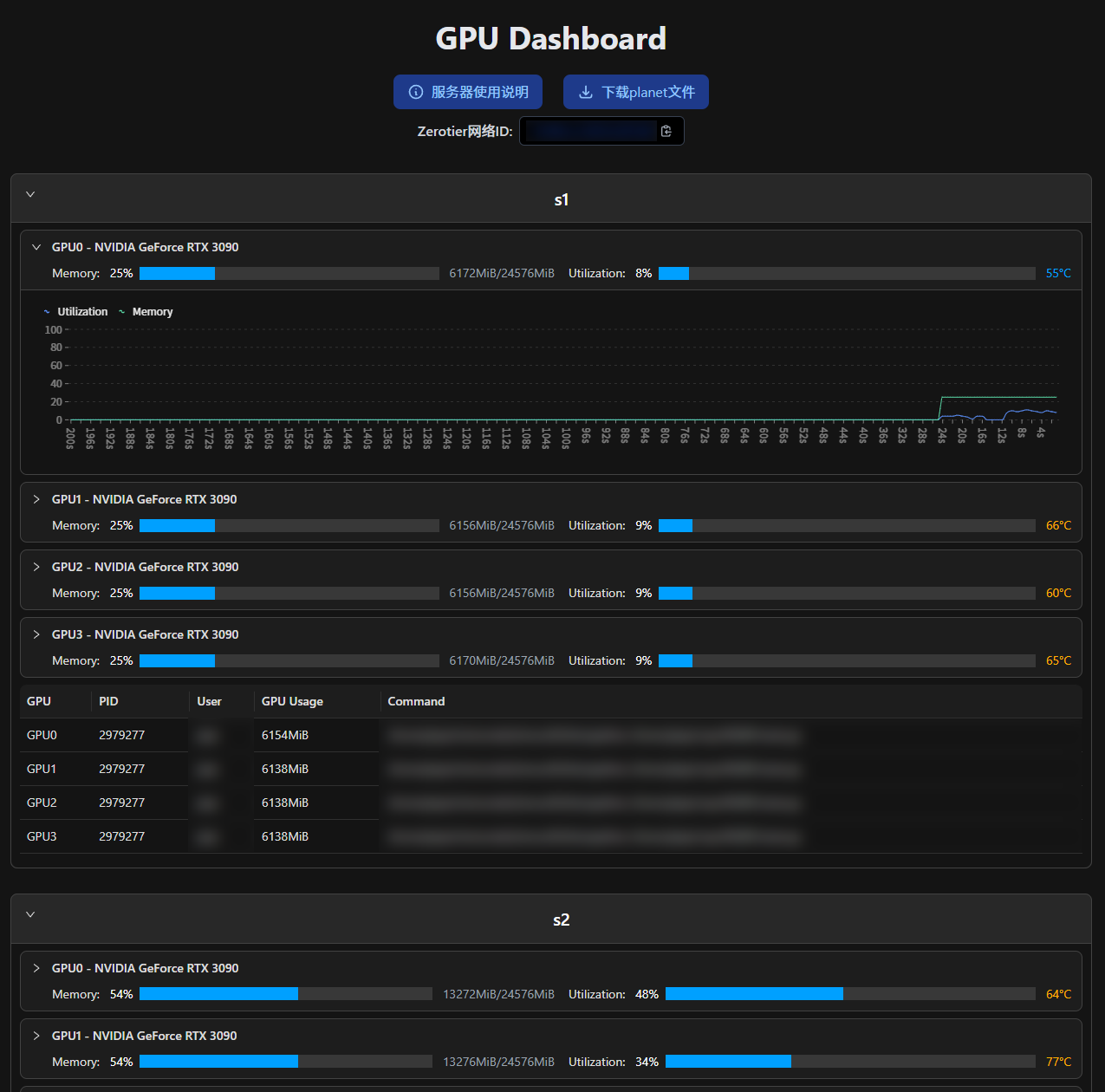 |
Old Solution: Get nvidia-smi Output via SSH
My previous frontend experience was limited to using Python to generate HTML, so I configured a GPU monitoring solution using my small host:
- Get the output of nvidia-smi via SSH command and parse information such as GPU memory usage from it.
- Based on the PID of GPU processes, get the user and command via the ps command.
- Use Python to output the above information as markdown, and convert it to HTML via Markdown.
- Configure cron to execute the above steps every minute, and configure the web root in nginx to the directory where the HTML is located.
The corresponding code is as follows:
CodeBlock Loading...
CodeBlock Loading...
CodeBlock Loading...
This solution has several obvious drawbacks: low update frequency, and it completely relies on backend updates, constantly refreshing data regardless of whether anyone is visiting.
New Solution: Frontend-Backend Separation
Actually, I've always wanted to implement a frontend-backend separated GPU monitoring system, running a fastapi on each server that returns the required data upon request. The recent development of NanNa Charging gave me the confidence to develop a frontend that fetches data from the API and renders it on the page.
fastapi Backend
Recently, I accidentally discovered that nvitop supports Python calls. I had always thought it could only visualize data through command line.
Great! This makes it much more convenient to get the required data, and the code is significantly reduced! ( •̀ ω •́ )✧
However, a troublesome issue is that our lab servers are behind a router, and the router is not under my control. Only SSH ports are forwarded.
I chose to use frp to map each server's API port to my small host on campus. My small host has quite a few web services configured, making it convenient to access APIs via domain names.
I was being silly before. Actually, I can completely use SSH (ssh -fN -L 8000:localhost:8000 user@ip) for port forwarding. This way, I can remove the frp-related code, and it will be easier to start the web service using docker.
CodeBlock Loading...
There are 3 environment variables in the code:
SUBURL: Used to configure the API path, such as specifying the server name.FRP_PATH: The path where frp and its configuration are located, used to map the API port to my small host on campus. If your servers can be accessed directly, just remove the related function and change the last line to0.0.0.0, then access via IP (or configure a domain name for each server).PORT: The port where the API is located.
Here I only wrote two interfaces , and actually only used one
/count: Returns how many GPUs there are./status: Returns specific status information. See the example below for the returned data. However, I also added two optional parameters:idx: Comma-separated numbers to get the status of specified GPUs.process: Used to filter returned processes. I set it to C when using it to only show compute tasks.
CodeBlock Loading...
Frontend Implemented with Vue
I'll be a bit lazy here , actually because I don't know how, and temporarily copied the UI originally generated by Python.
CodeBlock Loading...
CodeBlock Loading...
CodeBlock Loading...
CodeBlock Loading...
npm run build successfully got the release files. Configure nginx's root to that folder and you're done.
Implementation result: https://nvtop.njucite.cn/
Although the UI is still as ugly, at least it can refresh dynamically. Yay!
New UI
I'll draw the pie here first, waiting for me to come back after learning.( ̄_, ̄ )
More beautiful UI (I'm not sure if this has been achieved, I'm a design failure)
Add utilization line chart
Support dark mode
2024/12/27: Used nextjs to complete all the TODOs above. Additionally, implemented the feature to hide some hosts, and set hidden hosts as cookies for convenient display of the same state when reopened.
2025/03/11: nextjs updated with email login functionality, limited to authorized users only.
2025/09/18: Organized the code. Now the functionality is basically complete and convenient for others to deploy directly.
Full code available at: