はじめに
最近JPEGエンコーディングの方法を学んでおり、インターネットで多くの記事を探しましたが、すべての細部を十分に明確に説明している記事はほとんどないことがわかりました。そのためプログラミングで多くの落とし穴に遭遇しました。そこで、Pythonコードと組み合わせて、細部に関わる部分を説明する記事を書くことにしました。具体的なプログラムは私のGithub上のオープンソースプロジェクトを参照してください。
もちろん、この紹介とコードはまだ不完全であり、いくつかのエラーがあるかもしれません。入門ガイドとしてのみご利用ください。ご容赦ください。
JPEGファイルの各種マーカー
多くの記事がJPEGファイルのマーカーについて紹介しています。私も実際の画像に注釈を付けたドキュメント(クリックしてダウンロード)をアップロードしましたので、参考にしてください。
すべてのマーカーは0xff(16進数の255)で始まり、その後にこのブロックのデータのバイト数とこのブロックの情報を記述するデータが続きます。具体的には以下の図の通りです:
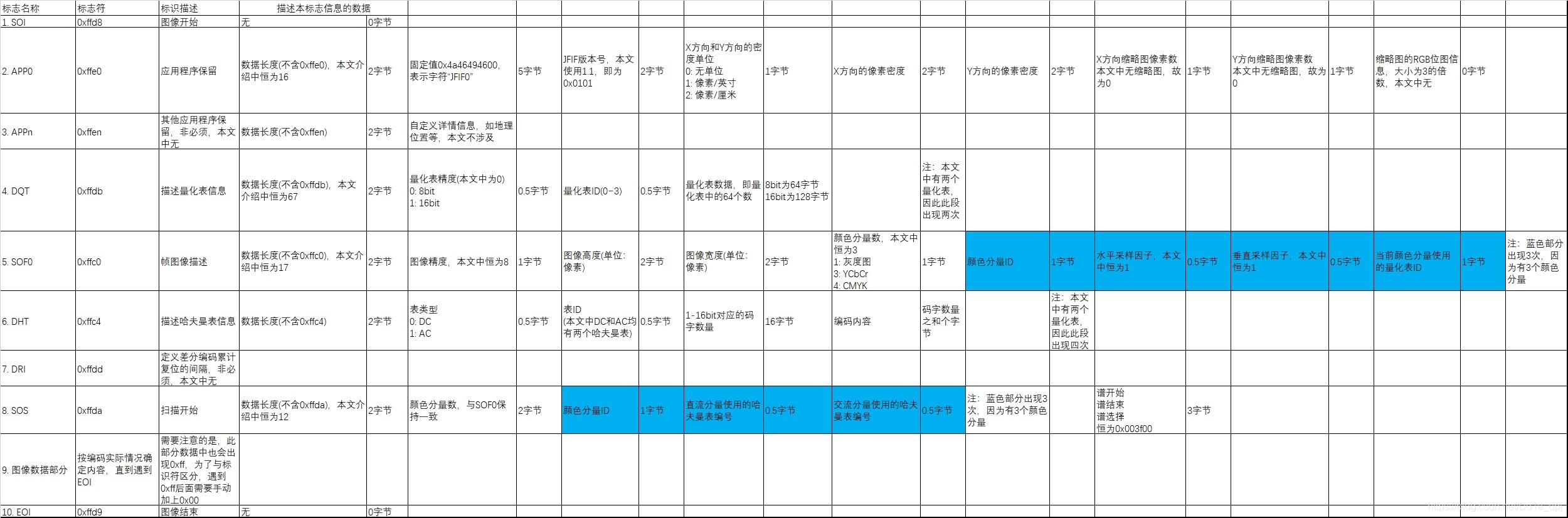
CodeBlock Loading...
ここまでで、画像データ部分以外はすべて書き込みました。画像データ部分がどのようにエンコードされているのか、また上記で言及した量子化やハフマン符号化が具体的にどのように実装されているのかについては、次のセクションをご覧ください。
JPEGエンコーディングの流れ
JPEGエンコーディングでは画像を8×8ブロックに分割する必要があるため、画像の高さと幅が8の倍数である必要があります。そのため、画像の内挿またはサンプリングの方法を採用して、画像にわずかな変更を加え、高さと幅が8の倍数になるようにします。数千〜数万ピクセルの画像にとって、この操作は画像全体のアスペクト比に大きな変化を与えません。
CodeBlock Loading...
色空間変換
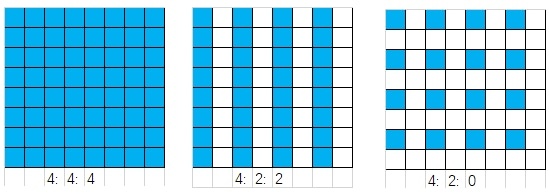
JPEG画像はYCbCr色空間を統一的に採用しています。これは、人間の目が輝度に対する知覚が強く、色度に対する知覚が弱いためです。そのため、CbとCr成分の圧縮を選択的に強化することで、画像の見た目を変えずに、より大きく画像サイズを縮小できます。YCbCr空間に変換した後、Cb Cr色成分をサンプリングして点数を減らすことで、より大きな圧縮を実現できます。一般的なサンプリング形式には4:4:4、4:2:2、4:2:0があります。これはSOF0マーカーの水平サンプリング係数と垂直サンプリング係数に対応しています。簡単にするため、本記事のすべてのサンプリング係数は1とし、サンプリングを行わず、1つのY成分に対して1つのCb Cr成分が対応します(4:4:4)。4:2:2は2つのY成分に対して1つのCb Cr成分、4:2:0は4つのY成分に対して1つのCb Cr成分となります。以下の図のように、各セルは1つのY成分に対応し、青いセルはCb Cr成分がサンプリングされるピクセル点です。
色空間変換の式は以下の通りです:
上記の演算はすべて四捨五入して整数にします。24ビットのRGB bmp画像では、R G B成分の範囲はすべて0-255です。簡単な数学的関係から、Y Cb Cr成分の範囲も0-255であることがわかります。JPEG画像では、通常、各成分から128を減算して、範囲に正と負の両方を持たせる必要があります。
Pythonではopencvライブラリの関数を使用して色空間変換を行うことができます:
CodeBlock Loading...
8×8ブロック分割
JPEGエンコーディングでは、各8×8ブロックを処理します。上から下、左から右の順序でデータ処理を行い、最後に各ブロックのデータを組み合わせます。各ブロックのY Cb Crの3つの色成分については、Y Cb Crの順序で同じ操作を行います(使用する量子化テーブルとハフマンテーブルは異なります)。
CodeBlock Loading...
DCT変換
DCT(離散コサイン変換)は、空間領域のデータを周波数領域に変換して演算を行います。これにより、周波数領域で選択的に高周波成分のデータを削減でき、画像の見た目に大きな影響を与えません。また、離散フーリエ変換と比較して、離散コサイン変換はすべて実数領域で演算が行われるため、コンピュータによる演算に有利です。離散コサイン変換の式は以下の通りです:
ここで です。JPEGでは、$M=N=8$ です。
もちろんopencvライブラリの関数を使用することもできます:
CodeBlock Loading...
量子化
DCT変換後、直流成分は8×8ブロックの最初の要素となり、低周波成分は左上に集中し、高周波成分は右下に集中します。選択的に高周波成分を除去するために、量子化操作を行います。これは実際には8×8ブロックの各要素をある定数で割ることです。量子化テーブルでは左上の要素が小さく、右下の要素が大きくなっています。量子化テーブルの例を以下に示します(Y成分とCb Cr成分は異なる量子化テーブルを使用):
CodeBlock Loading...
量子化プロセスのコード:
CodeBlock Loading...
量子化後、8×8ブロックの右下に多くの0が現れます。これらの0を集中させ、ランレングス符号化でより少ないデータ量を得るために、次にzigzagスキャンを行います。
zigzagスキャン
いわゆるzigzagスキャンとは、実際には8×8ブロックを以下の順序で64項目のリストに変換することです。
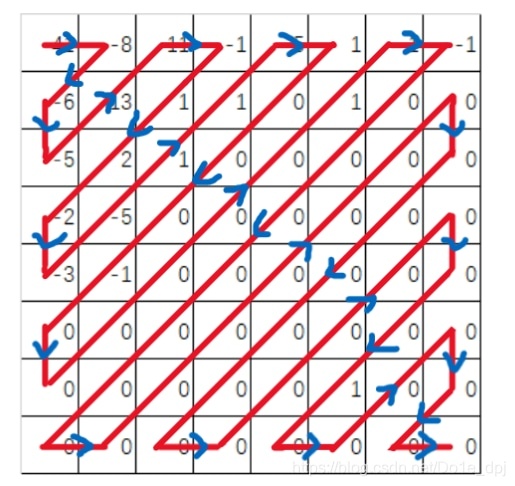
最終的に、このような長さ64のリストが得られます:(41, -8, -6, -5, 13, 11, -1, 1, 2, -2, -3, -5, 1, 1, -5, 1, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 1, 1, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0)。次の操作はすべてこのリストを例として行います。
注意すべき点は、量子化テーブルを保存する際にも、量子化テーブルを対応してzigzagスキャンし、この形式で保存する必要があることです。そうすることで、画像ビューアが正しい画像をデコードできます(私は最初、この細部で多くのデバッグ時間を費やしました)。本記事の最初のマーカー書き込みコードを参照してください。
CodeBlock Loading...
差分符号化(直流成分)
直流成分の値は通常大きく、同時に隣接する8×8ブロックの直流成分は非常に近い値になることが多いため、差分符号化を採用することでより多くのスペースを節約できます。いわゆる差分符号化とは、現在のブロックと前のブロックの直流成分の差分を保存することです。最初のブロックはそのまま保存します。注意すべき点は、Y Cb Crの3つの成分はそれぞれ対応して差分符号化を行い、各成分を対応して減算することです。直流成分nowblockdcをどのように符号化して保存するかについては、後述します。
CodeBlock Loading...
0のランレングス符号化(交流成分)
zigzagスキャン後、多くの0が集中します。交流成分のリストは以下の通りです:(-8, -6, -5, 13, 11, -1, 1, 2, -2, -3, -5, 1, 1, -5, 1, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 1, 1, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0)。
0のランレングス符号化では、毎回2つの数を保存します。2番目の数は非0の数で、1番目の数はその非0の数の前にいくつの0があるかを表します。最後に2つの0を終了マーカーとして追加します(特に注意:入力データが0で終わらない場合、2つの0を終了マーカーとして追加する必要はありません。このバグを見つけるのに長い時間がかかりました。以下のコードの23行目を参照してください)。上記のリストをランレングス符号化すると、以下が得られます:(0, -8), (0, -6), (0, -5), (0, 13), (0, 11), (0, -1), (0, 1), (0, 2), (0, -2), (0, -3), (0, -5), (0, 1), (0, 1), (0, -5), (0, 1), (3, -1), (6, 1), (0, 1), (0, -1),(27, 1), (0, 0)。このデータ長は42で、元の63と比較して少し減少しています。もちろん、ここでは特殊なデータを選択していますが、実際のデータにはより多くの0があり、すべて0の場合さえあり、符号化後のサイズはより小さくなります。
おそらく上記のデータで(27, 1)が赤くマークされていることに気づいたでしょう。これは第8セクションの符号化で、最初の数を保存する際に4ビットの数として保存するため、範囲が0〜15だからです。ここでは明らかに超過しているため、(15, 0), (11, 1)に分割する必要があります。(15, 0)は16個の0を表し、(11, 1)は11個の0の後に1があることを表します。
CodeBlock Loading...
JPEG特殊バイナリ符号化
上記の準備を経て、このセクションでは符号化された直流成分と交流成分がどのようにデータストリームとしてファイルに書き込まれるかを実際に紹介します。
JPEGエンコーディングでは、以下のバイナリ符号化形式があります:
CodeBlock Loading...
保存する数について、上記の形式に従って保存する必要があるビット長と実際に保存するバイナリ値を取得する必要があります。その法則を観察すると、正数の保存値はその実際のバイナリであり、ビット長もその実際のビット長であることがわかります。対応する負数も同じビット長で、バイナリ値はビットごとの否定後の値となります。0は保存する必要がありません。
CodeBlock Loading...
直流成分について、差分符号化後の値が-41であると仮定すると、上記の操作によりビット長が6で、保存するバイナリデータストリームが010110であることがわかります。データ6については、正規ハフマン符号化を使用してそのバイナリデータストリームを保存する必要があります。この部分は第9セクションで紹介します。まず6が保存するバイナリデータストリームを100と仮定すると、この8×8ブロックのある色成分の直流データは100010110として保存されます。
直流成分のバイナリデータストリームをファイルに書き込んだ後、次にこの8×8ブロックのこの色成分の交流成分を符号化します。ランレングス符号化後の値は以下の通りです:(0, -8), (0, -6), (0, -5), (0, 13), (0, 11), (0, -1), (0, 1), (0, 2), (0, -2), (0, -3), (0, -5), (0, 1), (0, 1), (0, -5), (0, 1), (3, -1), (6, 1), (0, 1), (0, -1),(15, 0), (11, 1) , (0, 0)。
まず(0, -8)を保存します。2番目の数について、同じ操作を行うと4ビットと0111が得られますが、直流成分と異なる点は、0x04に対して正規ハフマン符号化を行うことです。ここで上位4ビットは(0, -8)の最初の数、下位4ビットは2番目の数の保存ビット長です。0x04の正規ハフマン符号化後の保存値が1011であると仮定すると、(0, -8)は10110111として保存されます。次に(0, -6)などに対して同じ操作を行い、得られたデータストリームを順番にファイルに書き込みます。
もう一つの例として(6, 1)を取り上げます。ここで1は1として保存され、1ビットです。したがって0x61に対して正規ハフマン符号化を行います。1111011であると仮定すると、(6, 1)は11110111として保存されます。(15, 0)は0xf0の正規ハフマン符号化値のみを保存します。
上記のプロセスに従って1つの色成分(Yと仮定)のデータを書き込んだ後、次にこの8×8ブロックのCb色成分のデータを書き込み、続いてCr成分のデータを書き込みます。同じ方法で、左から右、上から下の順序で各8×8ブロックのデータを書き込んだ後、EOIマーカー(0xffd9)を書き込み、画像の終了とします。
注意:データの書き込み中に0xffが書き込まれたかどうかを検出する必要があります。マーカーの競合を防ぐために、後に0x00を追加する必要があります。
CodeBlock Loading...
正規ハフマン符号化
本記事で紹介する正規ハフマン符号化には4つの符号化テーブルがあり、それぞれ輝度直流成分、色度直流成分、輝度交流成分、色度交流成分に使用されます。
CodeBlock Loading...
上記のコードのstdhuffmanDC0などは、実際にマーカーに保存される値です。具体的にはマーカー紹介のコードを参照してください。この数字列の最初の16個の数字(0, 0, 7, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0)は、符号化後の長さが1〜16ビットの数がそれぞれいくつあるかを表し、その後ろの12個の数は最初の16個の数字の合計と一致します。stdhuffmanDC0が実際に記述しているのは以下の図です:
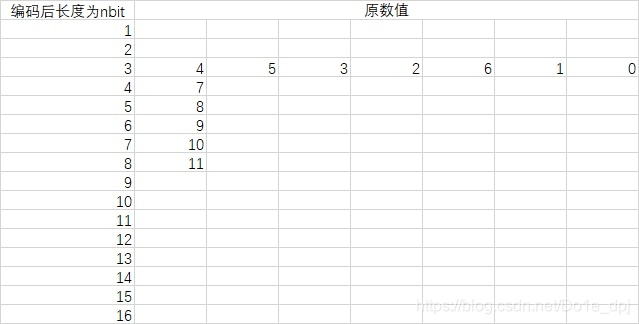
現在、各元データが符号化された後のデータ長しかわかっておらず、実際の値はわかっていません。
正規ハフマン符号化には独自のルールがあります:
- 最小符号化長の最初の数の符号は0です;
- 同じ符号化長の符号は連続しています;
- 次の符号化長(jと仮定)の最初の数の符号aは、前の符号化長(iと仮定)の最後の数の符号bに依存します。つまり
a=(b+1)<<(j-i)です。
ルール1から、4の符号が000であることがわかります。ルール2から、5の符号は001、3の符号は010、2の符号は011...、0の符号は110となります。ルール3から、7の符号は1110、8の符号は11110...となります。
CodeBlock Loading...
最終的に得られるハフマン辞書はかなり長いため、私のGithubプロジェクトで確認できます。その法則を見つけることで、write_num関数で辞書のインデックスがどのように求められているかを理解できます。